

The evolution of language models is nothing less than a super-charged industrial revolution. Google lit the spark in 2017 with the development of transformer models, which enable language models to focus on, or attend to, key elements in a passage of text. The next breakthrough — language model pre-training, or self-supervised learning — came in 2020 after which LLMs could be significantly scaled up to drive Generative Pretrained Transformer 3 (GPT-3).
While large language models (LLMs) like ChatGPT are far from perfect, their development will only accelerate in the months and years ahead. The rapid expansion of the ChatGPT plugin store hints at the rate of acceleration. To anticipate how they will shape the investment industry, we need to understand their origins and their path thus far.
So what were the six critical stages of LLMs’ early evolution?
The Business of GPT-4: How We Got Here
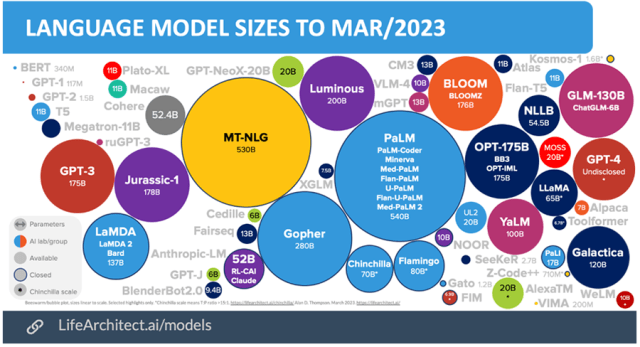
ChatGPT and GPT-4 are just two of the many LLMs that OpenAI, Google, Meta, and other organizations have developed. They are neither the largest nor the best. For instance, we prefer LaMDA for LLM dialogue, Google’s Pathways Language Model 2 (PaLM 2) for reasoning, and Bloom as an open-source, multilingual LLM. (The LLM leaderboard is fluid, but this site on GitHub maintains a helpful overview of model, papers, and rankings.)
So, why has ChatGPT become the face of LLMs? In part, because it launched with greater fanfare first. Google and Meta each hesitated to launch their LLMs, concerned about potential reputational damage if they produced offensive or dangerous content. Google also feared its LLM might cannibalize its search business. But once ChatGPT launched, Google’s CEO Sundar Pichai, reportedly declared a “code red,” and Google soon unveiled its own LLM.
GPT: The Big Guy or the Smart Guy?
The ChatGPT and ChatGPT Plus chatbots sit on top of GPT-3 and GPT-4 neural networks, respectively. In terms of model size, Google’s PaLM 2, NVIDIA’s Megatron-Turing Natural Language Generation (MT-NLG), and now GPT-4 have eclipsed GPT-3 and its variant GPT-3.5, which is the basis of ChatGPT. Compared to its predecessors, GPT-4 produces smoother text of better linguistic quality, interprets more accurately, and, in a subtle but significant advance over GPT-3.5, can handle much larger input prompts. These improvements are the result of training and optimization advances — additional “smarts” — and probably the pure brute force of more parameters, but OpenAI does not share technical details about GPT-4.
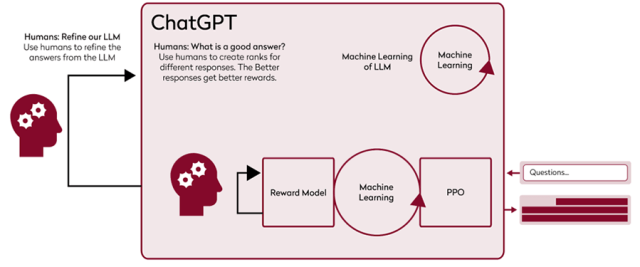
ChatGPT Training: Half Machine, Half Human
ChatGPT is an LLM that is fine-tuned through reinforcement learning, specifically reinforcement learning from human feedback (RLHF). The process is simple in principle: First humans refine the LLM on which the chatbot is based by categorizing, on a massive scale, the accuracy of the text the LLM produces. These human ratings then train a reward model that automatically ranks answer quality. As the chatbot is fed the same questions, the reward model scores the chatbot’s answers. These scores go back into fine-tuning the chatbot to produce better and better answers through the Proximal Policy Optimization (PPO) algorithm.
ChatGPT Training Process
The Machine Learning behind ChatGPT and LLMs
LLMs are the latest innovation in natural language processing (NLP). A core concept of NLP are language models that assign probabilities to sequences of words or text — S = (w1,w2, … ,wm) — in the same way that our mobile phones “guess” our next word when we are typing text messages based on the model’s highest probability.
Steps in LLM Evolution
The six evolutionary steps in LLM development, visualized in the chart below, demonstrate how LLMs fit into NLP research.
The LLM Tech (R)Evolution

1. Unigram Models
The unigram assigns each word in the given text a probability. To identify news articles that describe fraud in relation to a company of interest, we might search for “fraud,” “scam,” “fake,” and “deception.” If these words appear in an article more than in regular language, the article is likely discussing fraud. More specifically, we can assign a probability that a piece of text is about. More specifically, we can assign a probability that a piece of text is about fraud by multiplying the probabilities of individual words:
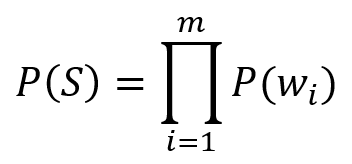
In this equation, P(S) denotes the probability of a sentence S, P(wi) reflects the probability of a word wi appearing in a text about fraud, and the product taken over all m words in the sequence, determines the probability that these sentences are associated with fraud.
These word probabilities are based on the relative frequency at which the words occur in our corpus of fraud-related documents, denoted as D, in the text under examination. We express this as P(w) = count(w) / count(D), where count(w) is the frequency that word w appears in D and count(D) is D’s total word count.
A text with more frequent words is more probable, or more typical. While this may work well in a search for phrases like “identify theft,” it would not be as effective for “theft identify” despite both having the same probability. The unigram model thus has a key limitation: It disregards word order.

2. N-Gram Models
“You shall know a word by the company it keeps!” — John Rupert Firth
The n-gram model goes further than the unigram by examining subsequences of several words. So, to identify articles relevant to fraud, we would deploy such bigrams as “financial fraud,” “money laundering,” and “illegal transaction.” For trigrams, we might include “fraudulent investment scheme” and “insurance claim fraud.” Our fourgram might read “allegations of financial misconduct.”
This way we condition the probability of a word on its preceding context, which the n-gram estimates by counting the word sequences in the corpus on which the model was trained.
The formula for this would be:
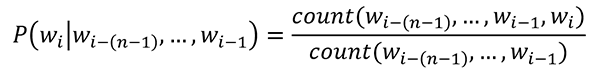
This model is more realistic, giving a higher probability to “identify theft” rather than “theft identify,” for example. However, the counting method has some pitfalls. If a word sequence does not occur in the corpus, its probability will be zero, rendering the entire product as zero.
As the value of the “n” in n-gram increases, the model becomes more precise in its text search. This enhances its ability to identify pertinent themes, but may lead to overly narrow searches.
The chart below shows a simple n-gram textual analysis. In practice, we might remove “stop words” that provide no meaningful information, such as “and,” “in,” “the,” etc., although LLMs do keep them.
Understanding Text Based on N-Grams
| Unigram | Modern-slavery practices including bonded-labor have been identified in the supply-chain of Company A |
| Bigrams | Modern-slavery practices including bonded-labor have been identified in the supply-chain of Company A |
| Trigrams | Modern-slavery practices including bonded-labor have been identified in the supply-chain of Company A |
| Fourgrams | Modern-slavery practices including bonded-labor have been identified in the supply-chain of Company A |
3. Neural Language Models (NLMs)
In NLMs, machine learning and neural networks address some of the shortcomings of unigrams and n-grams. We might train a neural network model N with the context (wi–(n–1), … ,wi–1) as the input and wi as the target in a straightforward manner. There are many clever tricks to improve language models, but fundamentally all that LLMs do is look at a sequence of words and guess which word is next. As such, the models characterize the words and generate text by sampling the next word according to the predicted probabilities. This approach has come to dominate NLP as deep learning has developed over the last 10 years.

4. Breakthrough: Self-Supervised Learning
Thanks to the internet, larger and larger datasets of text became available to train increasingly sophisticated neural model architectures. Then two remarkable things happened:
First, words in neural networks became represented by vectors. As the training datasets grow, these vectors arrange themselves according to the syntax and semantics of the words.
Second, simple self-supervised training of language models turned out to be unexpectedly powerful. Humans no longer had to manually label each sentence or document. Instead, the model learned to predict the next word in the sequence and in the process also gained other capabilities. Researchers realized that pre-trained language models provide great foundations for text classification, sentiment analysis, question answering, and other NLP tasks and that the process became more effective as the size of the model and the training data grew.
This paved the way for sequence-to-sequence models. These include an encoder that converts the input into a vector representation and a decoder that generates output from that vector. These neural sequence-to-sequence models outperformed previous methods and were incorporated into Google Translate in 2016.
5. State-of-the-Art NLP: Transformers
Until 2017, recurrent networks were the most common neural network architecture for language modeling, long short-term memory (LSTM), in particular. The size of LSTM’s context is theoretically infinite. The models were also made bi-directional, so that also all future words were considered as well as past words. In practice, however, the benefits are limited and the recurrent structure makes training more costly and time consuming: It’s hard to parallelize the training on GPUs. For mainly this reason, transformers supplanted LSTMs.
Transformers build on the attention mechanism: The model learns how much weight to attach to words depending on the context. In a recurrent model, the most recent word has the most direct influence on predicting the next word. With attention, all words in the current context are available and the models learn which ones to focus on.
In their aptly titled paper, “Attention is All You Need,” Google researchers introduced Transformer sequence-to-sequence architecture, which has no recurrent connections except that it uses its own output for context when generating text. This makes the training easily parallelizable so that models and training data can be scaled up to previously unheard of sizes. For classification, the Bidirectional Encoder Representations from Transformers (BERT) became the new go-to model. For text generation, the race was now on to scale up.

6. Multimodal Learning
While standard LLMs are trained exclusively on textual data, other models — GPT-4, for example — include images or audio and video. In a financial context, these models could examine chart, images, and videos, from CEO interviews to satellite photography, for potentially investable information, all cross-referenced with news flow and other data sources.
Criticism of LLMs
Transformer LLMs can predict words and excel at most benchmarks for NLP tasks, including answering questions and summarization. But they still have clear limitations. They memorize rather than reason and have no causal model of the world beyond the probabilities of words. Noam Chomsky described them as “high tech plagiarism,” and Emily Bender et al. as “stochastic parrots.” Scaling up the models or training them on more text will not address their deficits. Christopher D. Manning and Jacob Browning and Yann LeCun, among other researchers, believe the focus should be on expanding the models’ technology to multimodality, including more structured knowledge.
LLMs have other scientific and philosophical issues. For example, to what extent can neural networks actually learn the nature of the world just from language? The answer could influence how reliable the models become. The economic and environmental costs of LLMs could also be steep. Scaling up has made them expensive to develop and run, which raises questions about their ecological and economic sustainability.
Artificial General Intelligence (AGI) Using LLMs?
Whatever their current limitations, LLMs will continue to evolve. Eventually they will solve tasks far more complex than simple prompt responses. As just one example, LLMs can become “controllers” of other systems and could in principle guide elements of investment research and other activities that are currently human-only domains. Some have described this as “Baby AGI,” and for us it is easily the most exciting area of this technology.
Baby AGI: Controller LLMs
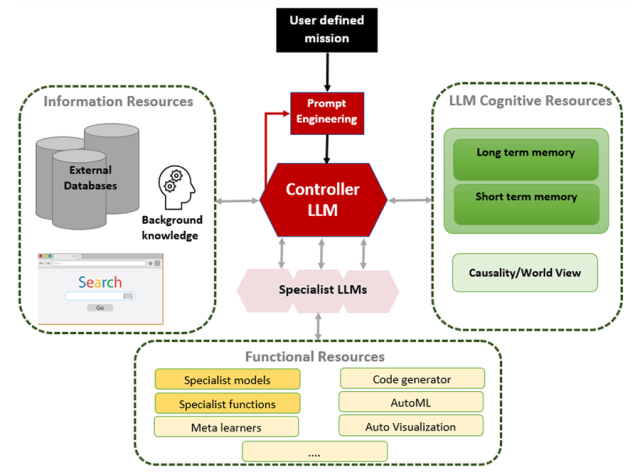

The Next Steps in the AI Evolution
ChatGPT and LLMs more generally are powerful systems. But they are only scratching the surface. The next steps in the LLM revolution will be both exciting and terrifying: exciting for the technically minded and terrifying for the Luddites.
LLMs will feature more up-to-the-minute information, increased accuracy, and the ability to decipher cause and effect. They will better replicate human reasoning and decision making.
For high-tech managers, this will constitute an incredible opportunity to cut costs and improve performance. But is the investment industry as a whole ready for such disruptive changes? Probably not.
Luddite or tech savant, if we cannot see how to apply LLMs and ChatGPT to do our jobs better, it is a sure bet that someone else will. Welcome to investing’s new tech arms race!
For further reading on this topic, check out The Handbook of Artificial Intelligence and Big Data Applications in Investments, by Larry Cao, CFA, from CFA Institute Research Foundation.
If you liked this post, don’t forget to subscribe to the Enterprising Investor.
All posts are the opinion of the author(s). As such, they should not be construed as investment advice, nor do the opinions expressed necessarily reflect the views of CFA Institute or the author’s employer.
Image credit: ©Getty Images / imaginima
Professional Learning for CFA Institute Members
CFA Institute members are empowered to self-determine and self-report professional learning (PL) credits earned, including content on Enterprising Investor. Members can record credits easily using their online PL tracker.










